



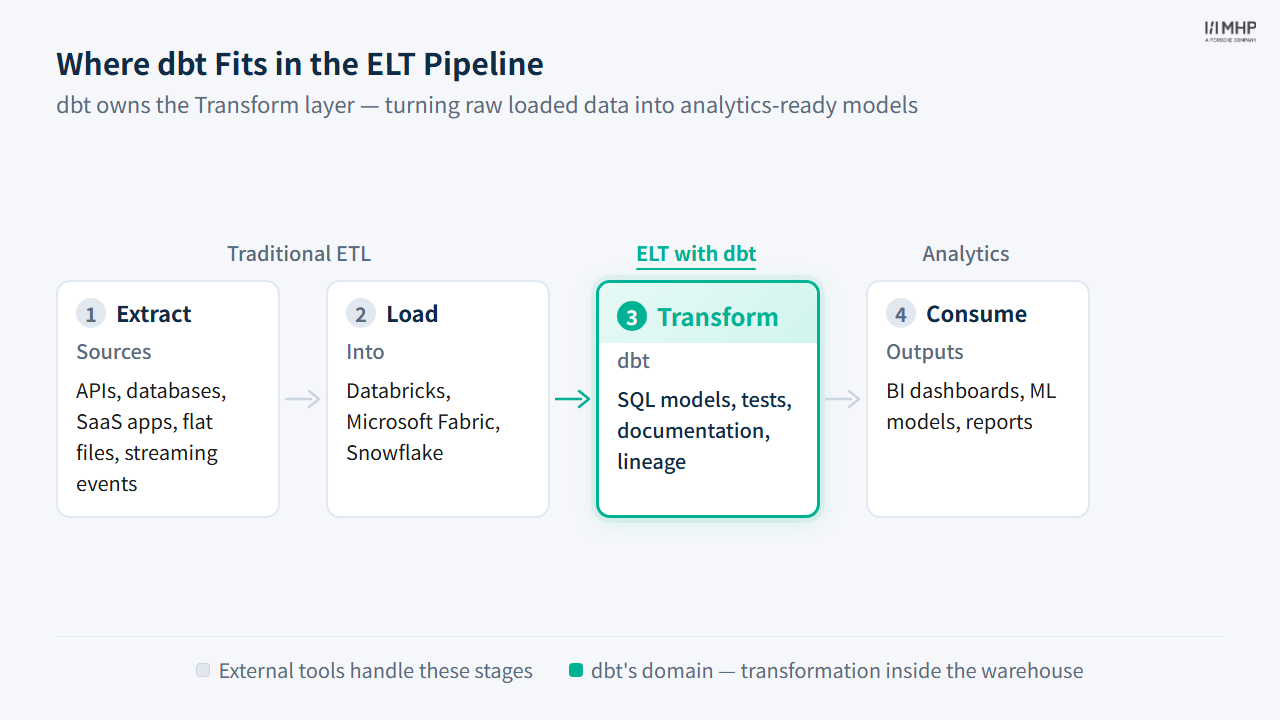
flowchart LR
subgraph Staging ["Staging"]
ST1["stg_nyc_taxi_trips"]
ST2["stg_taxi_zone_lookup"]
end
subgraph Silver ["Silver"]
SI1["silver_nyc_taxi_cleaned"]
SI2["silver_nyc_taxi_enriched"]
end
subgraph Gold ["Gold KPIs"]
G1["kpi_trips_by_hour"]
G2["kpi_revenue_by_hour"]
G3["kpi_top_pickup_zones"]
G4["kpi_data_quality_metrics"]
end
ST1 --> SI1
SI1 --> SI2
ST2 --> SI2
SI2 --> G1
SI2 --> G2
SI2 --> G3
SI2 --> G4
classDef staging fill:#475569,color:#fff,stroke:#334155
classDef silver fill:#0369a1,color:#fff,stroke:#075985
classDef gold fill:#01065c,color:#fff,stroke:#000940
class ST1,ST2 staging
class SI1,SI2 silver
class G1,G2,G3,G4 gold
Module 4: dbt Pipeline
Transform-as-code on Snowflake and Databricks
![]()
Duration: 75 min — Animation (3) · Think & Discuss (7) · Theory (15) · Quiz (3) · Practice (47)
NoteBefore you start — compute
dbt has no own compute — it runs SQL on your configured backend:
| Target | Workshop compute | Role | You need |
|---|---|---|---|
| Snowflake (default lab) | DE_WORKSHOP_WH |
DE_WORKSHOP_ROLE |
Warehouse Started + role in Snowsight (Exercise: Snowflake § role); role: DE_WORKSHOP_ROLE in profiles.yml |
| Databricks (optional compare) | de-workshop-wh SQL warehouse |
(PAT + UC grants) | Not your PySpark cluster — dbt uses DATABRICKS_HTTP_PATH (Exercise: Databricks § cluster vs warehouse) |
Lab runs in Codespaces terminal — no Databricks cluster attach required for dbt itself.
Lab: Exercise: dbt — complete Configure .env before Step 1.
1. Animation
2. Think & Discuss
Situation: Marcus’s board asked: “Where does each dashboard number come from?” Elena adds dbt on top of Snowflake for tests, lineage, and SQL-first transforms. Priya wants revenue pages and a data quality scorecard. James will cross-check kpi_data_quality_metrics in SQL before Priya publishes the scorecard.
Prompts:
- What problem does Marcus have that Snowflake SQL alone did not fully solve?
- Is dbt a replacement for Snowflake? State dbt’s job in one sentence.
- Marcus clicks a revenue tile in Power BI — how would you prove which model and source table that number came from?
- Name two tests you would add so bad data never silently breaks a KPI.
- Which Gold KPI table feeds Priya’s data quality scorecard? What would it measure?
3. Theory
Elena: We keep Snowflake as the engine. dbt owns transform SQL, tests, and lineage — what Marcus’s board asked for.
NoteHorizon Catalog
Snowflake Horizon Catalog is the governance umbrella (tags, masking, lineage) — parallel to Unity Catalog in the Databricks track.
3.1 Theory: dbt Essentials
What is dbt?
Before diving into dbt, consider the two user personas on Databricks: Spark/Python engineers who build pipelines in notebooks and SQL analysts who write queries in SQL Warehouse or external BI tools. dbt bridges this gap — it lets both personas collaborate on the same codebase using SQL, while the underlying engine (Spark or Snowflake) handles execution.
dbt (data build tool) is a transformation framework that:
- Turns SQL
SELECTstatements into managed tables/views - Adds testing, documentation, and lineage to SQL
- Runs on top of existing compute (Databricks, Snowflake, BigQuery, etc.)
- Does not handle ingestion — it assumes Bronze tables already exist
Problems dbt solves
Before dbt, teams like Marcus’s at YellowLine NYC typically face:
| Pain Point | Without dbt | With dbt |
|---|---|---|
| Complex SQL | Hundreds of lines of CREATE TABLE / INSERT boilerplate |
One SELECT per model — dbt handles DDL/DML |
| Dependency management | Manually ordered scripts; break when upstream changes | ref() builds a DAG — dbt runs models in correct order |
| Testing | No automated data quality checks; errors found in dashboards | Built-in tests (not_null, unique, accepted_values) |
| Documentation | Stale wikis or no docs at all | Auto-generated docs + interactive lineage graph (dbt docs) |
| Code reuse | Copy-pasted SQL across notebooks and scripts | Macros and packages — DRY principle for SQL |
| Version control | Notebooks in folders; no code review | Git-native workflow with PRs and CI/CD |
Software engineering for SQL
dbt’s core insight is applying software engineering best practices — version control, testing, modularity, CI/CD, documentation — to SQL transformations. This is exactly what Elena needed when she proposed dbt to address the board’s governance requirements.
Core Concepts
| Concept | What It Does | Example |
|---|---|---|
| Model | SQL SELECT → table/view | silver_nyc_taxi_cleaned.sql |
| ref() | Reference another model | { ref('silver_nyc_taxi_enriched') } |
| source() | Reference a raw table | { source('bronze', 'nyc_taxi_trips') } |
| Test | Validate data expectations | not_null, accepted_values |
| Macro | Reusable SQL function | { time_of_day('pickup_hour') } |
| Seed | CSV → table | taxi_zone_lookup.csv |
How ref() builds the DAG — each ref() call creates a dependency edge. dbt reads all model files, resolves the dependency graph, and runs models in topological order:
NoteWorkshop path: dbt Core CLI (not dbt Cloud)
This module runs dbt Core in your Codespace terminal — dbt deps, run, test, build, and docs serve — with profiles.yml pointing at Snowflake or Databricks. You do not need a dbt Cloud account for the lab.
Optional tooling (facilitator horizon): the dbt VS Code extension works with local Core projects (inline validation, DAG view). dbt Fusion (Rust-based engine) and dbt Canvas (visual editor) are dbt Cloud / platform features — useful to know for production, but not part of today’s CLI lab.
Cross-Platform SQL
dbt uses target.type to write platform-specific SQL:
{%- if target.type == 'snowflake' -%}
dayname(pickup_datetime)
{%- else -%}
date_format(pickup_datetime, 'EEEE')
{%- endif -%}This conditional compilation is powered by Jinja — a templating engine embedded in dbt SQL files. Beyond target.type, Jinja provides ref() and source() for dependency management, macros for reusable SQL snippets (similar to functions in Python), and configuration blocks ({ config(...) }) that control how each model is materialized. The result: SQL files that are both portable across platforms and DRY (Don’t Repeat Yourself).
Materialization Strategies
Every dbt model must choose a materialization — the strategy for how the SELECT statement becomes a database object:
| Materialization | What it creates | When to use | Tradeoff |
|---|---|---|---|
| view | A database view (query runs on access) | Simple transforms, always-fresh data | Slow queries on large tables |
| table | A physical table (rebuilt on each run) | Gold KPI aggregations, stable lookups | Storage cost; stale between runs |
| incremental | Appends/merges only new rows | Large Silver tables with append-only sources | Complexity: requires is_incremental() logic |
| ephemeral | No database object (inlined as CTE) | Intermediate logic shared via ref() |
Not queryable outside dbt; no testing |
| dynamic_table | Snowflake-managed incremental refresh | Near-real-time streaming (Snowflake only) | Workshop Module 8; target_lag controls freshness |
| materialized_view | Database-managed refresh | Near-real-time on Databricks adapter | Adapter-specific; not used in this Snowflake lab |
-- Example: incremental materialization for a large Silver table
{{ config(
materialized = 'incremental',
unique_key = 'trip_id'
) }}
SELECT *
FROM {{ source('bronze', 'nyc_taxi_trips') }}
WHERE fare_amount > 0
{% if is_incremental() %}
AND tpep_pickup_datetime > (SELECT MAX(tpep_pickup_datetime) FROM {{ this }})
{% endif %}For this workshop, most models use table materialization — simplicity first. Incremental patterns appear in production (Module 5) and streaming (Module 8).
Testing Framework
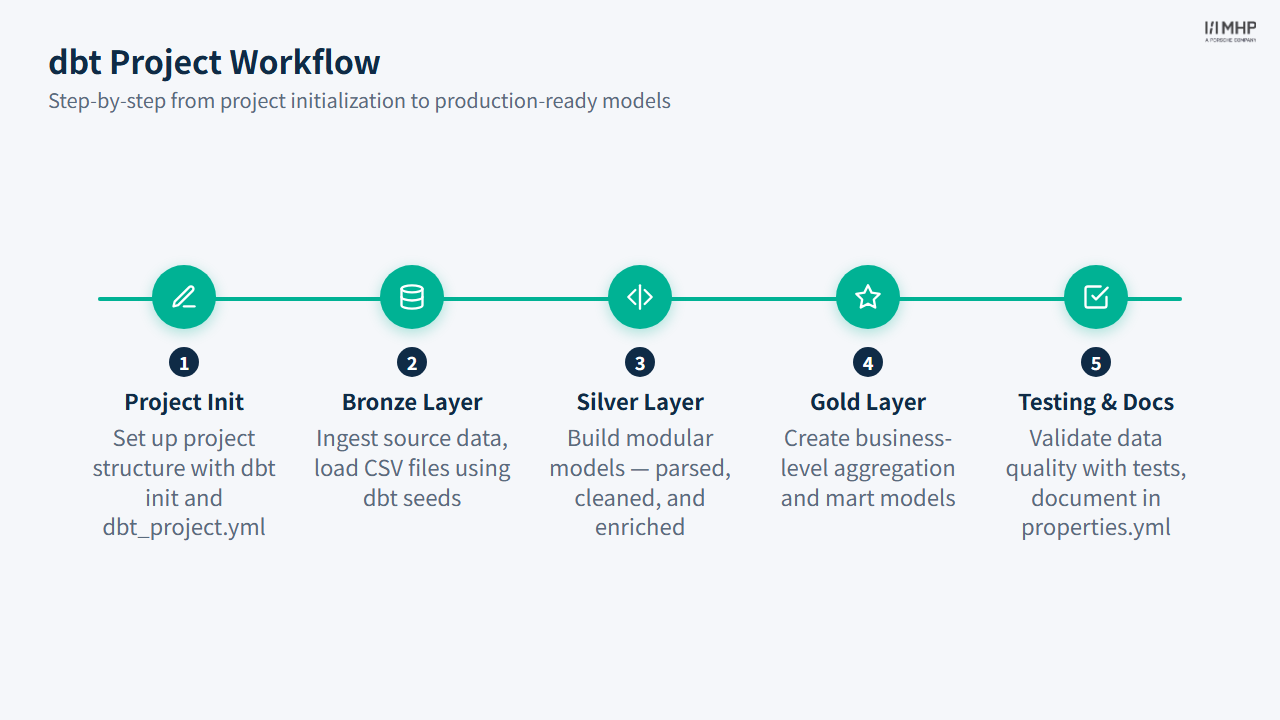
The slide above walks through the full dbt project workflow: Init (dbt init to scaffold the project and configure profiles.yml), Bronze (registering raw source tables via source() declarations), Silver (cleaning and transforming with ref() chains), Gold (building KPI aggregations for dashboards), and finally Testing & Docs (dbt build to run + test, then dbt docs generate to produce lineage graphs and data dictionaries). Each phase maps to a step in the medallion architecture you have already built in Modules 2 and 3.
dbt’s testing framework is what sets it apart from ad-hoc SQL scripts. Tests are first-class citizens — they run alongside your models via dbt build (which combines run + test in one command).
Built-in generic tests cover the most common data quality checks:
not_null— column has no nulls (essential for primary keys)unique— no duplicate values (critical for IDs)accepted_values— column only contains expected values (e.g.,payment_type_desc IN ('Credit card', 'Cash'))relationships— foreign key integrity between models
# models/silver/_silver.yml (this project uses _silver.yml, _gold.yml, _staging.yml)
models:
- name: silver_nyc_taxi_enriched
columns:
- name: trip_id
tests: [unique, not_null]
- name: payment_type_desc
tests:
- accepted_values:
values: ['Credit card', 'Cash', 'No charge', 'Dispute', 'Unknown']
- name: fare_amount
tests:
- not_nullBeyond built-in tests, you can write custom SQL tests (tests/assert_revenue_positive.sql) that validate business rules — for example, “Gold revenue KPIs must never be negative.” Every test result is logged and surfaced in dbt docs, creating an auditable data quality record.
Always use dbt build
In production, always run dbt build (which executes run + test together) instead of separate dbt run followed by dbt test. If a model’s tests fail, dbt build stops downstream models from running — preventing bad data from propagating to Gold tables and dashboards. This single habit prevents the most common production data quality incidents.
dbt is not an ingestion tool
A common mistake is trying to use dbt for Bronze ingestion — reading files from cloud storage and loading them into tables. dbt cannot do this. It assumes Bronze tables already exist and only transforms data via SELECT statements. Ingestion is the job of Databricks (spark.read.parquet()) or Snowflake (COPY INTO). If you find yourself wanting to write CREATE TABLE ... AS SELECT FROM EXTERNAL LOCATION, that’s an ingestion concern — not a dbt model.
3.2 Live demo walkthrough
# Install packages
dbt deps
# Batch medallion only (exclude optional ML + streaming models)
dbt run --target databricks --exclude tag:ml tag:streaming
dbt test --target databricks --exclude tag:ml tag:streaming
# Run SAME models against Snowflake backend
dbt run --target snowflake --exclude tag:ml tag:streaming
dbt test --target snowflake --exclude tag:ml tag:streaming
# Compare Gold KPI outputs — they should match! Expect PASS=17 on run (1 hook + 16 models).
# Generate and view documentation
dbt docs generate --target snowflake
dbt docs serve3.3 Key Takeaways
- dbt adds testing, docs, and lineage to SQL transformations — it is the governance layer on top of compute engines
- Same models, different backends —
target.typeand Jinja templating enable cross-platform SQL without code duplication - dbt does not replace Databricks or Snowflake — it sits on top as a transformation-only layer (no ingestion)
- refs create a dependency graph (DAG) — dbt knows the correct execution order and builds models in the right sequence
- Materialization choice (view, table, incremental) controls the tradeoff between freshness, cost, and complexity
dbt build(run + test together) is the production standard — failing tests block downstream models- This workshop uses dbt Core CLI locally — production scheduling is typically GitHub Actions (or cron + orchestrator) running
dbt build; dbt Cloud is an optional managed alternative (see Module 5)
4. Quiz
Quiz: Module 4 — dbt Pipeline Quiz
Before moving on, make sure you can answer:
- What is the difference between
ref()andsource()— when would you use each? - Name two materialization types and explain when you’d choose one over the other.
- What does
dbt builddo thatdbt runalone does not, and why does it matter in production? - Why can’t dbt load raw Parquet files from cloud storage into Bronze tables?
5. Practice


Hands-on lab
- Exercise: dbt Pipeline — required (Codespaces terminal)
Project: dbt_project/ targeting Snowflake.
TipSelf-paced — Power BI (after this lab)
When all 12 Gold kpi_* tables exist, Priya can connect Power BI Desktop (free) to the same schema:
- Self-paced lab (~45–60 min): Exercise: Power BI Dashboard — five pages, all 12 KPIs
- Install & connect: Power BI setup
- DAX & theme reference: Power BI DAX & theme reference
Priya / Power BI: Revenue & Payments pages plus kpi_data_quality_metrics scorecard.
Next module
Module 5: Production Patterns — Elena asks: What executes every night when we are not in the room?